수업시간 실습으로 AWS EC2의 인스턴스 종류에 따른 성능 테스트를 하고자 한다.
이때 인스턴스 유형은 t2nano, t2xlarge, t4nano, t4xlarge, c5large, m5large, c5xlarge, m5xlarge이렇게 8가지 종류로 변경해보며 성능테스트를 진행하려고 한다. 그리고 이를 통해 어떤 인스턴스 유형을 사용하는 것이 어떤 업무에 적합한 지 알아가고자 한다.
인스턴스 유형 이름의 의미

테스트는 HTTP 부하테스트 도구인 hey 를 사용해주었다.
hey 다운 받는 법
sudo apt update
sudo apt install hey
부하테스트 코드
from flask import Flask
app = Flask(__name__)
@app.route("/api/calc")
def calc():
x = sum([i**2 for i in range(1, 100000)]) # CPU 부하
return str(x) #단순 문자열로 반환
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8080)
hey 테스트 실행 코드 (이때 포트번호는 python 파일에서 설정한 포트번호를 의미=EC2의 포트번호)
hey -n 1000 -c 50 http://localhost:8080/api/calc
이때 포트번호는 EC2 설정할때 작성한 포트번호로 넣어주면 되고 localhost 부분에 퍼블릭 IP주소를 넣어주면 된다.
그리고 -n 뒤에있는 1000은 요청량 -c 뒤에있는 50은 동시접속자 수 인데 요청량을 변경해가면서 실험을 진행했다.
이때 가장 중요한 포인트‼️
이 모든 실행 과정은 인스턴스 내에서 실행을 한 것 이다.
hey의 설치 및 실행 또한 인스턴스 내에서 실행 되어야한다.
그 이유는?
만약 연산을 수행하는 pyhton 코드는 인스턴스 내에서 수행하고 hey는 인스턴스가 아닌 나의 컴퓨터 환경에서 실행을 한다고 가정해보자
그렇게 된다면 실행속도에 네트워크와 통신하는 시간 또한 포함되기 때문에 실험결과가 부정확해질 수 있다.
그러므로 실험을 진행할 인스턴스에 hey를 설치하고 연산을 수행하는 python 파일을 저장해주어야 한다.
모든 인스턴스에 설치하는게 너무 번거로워⁉️
실험을 진행할 모든 인스턴스에 hey를 설치하고 python 파일을 작성하고 flask를 작성할 생각을 하면 아찔해진다....

하지만 우리에겐 AMI라는 사기캐가 있다 ㄷㄷ
AMI란 무엇인가?
AMI(Amazon Machine Image)는 EC2 인스턴스를 만들 때 사용하는 ‘컴퓨터의 설계도’ 같은 것이다.
이게 무슨 말인가 하면 만약 내가 하나의 인스턴스를 만들었다고 가정해보자 그리고 여기에 anaconda, hey, flask 등을 설치하고 web 이라는 이름의 폴더를 두고 test_calc 라는 파이썬 파일을 web 폴더 안에 저장해둔다고 하자.
그리고 이 인스턴스로 이미지를 생성한 다음 만들어진 AMI로 다른 인스턴스를 만든다고 하면 인스턴스의 유형을 다른 걸 선택하더라도
이 AMI로 만들어진 새로운 인스턴스에 anaconda, hey, flask가 이미 설치되어 있고 web폴더가 이미 존재하며 test_calc.py 라는 파일도 이미 web폴더안에 존재하는 것이다.
한마디로 나만의 커스텀 인스턴스 틀을 만들 수 있도록 도와주는 것이다.
아무튼 이 실험을 하기 위해 실험에 필요한게 모두 갖추어진 인스턴스로 AMI를 생성하고 인스턴스 유형을 바꿔 가며 hey로 부하테스트를 진행하였다.
실험내용
테스트 대상 인스턴스

평균응답시간


💵가격대비 성능 요약

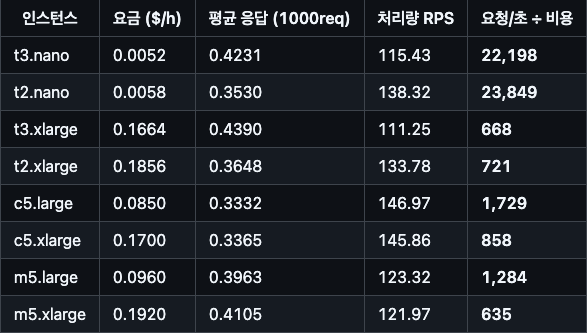
🔎 인스턴스별 특성 요약
✅ T 계열 (t2, t3)
-버스트 성능 기반**: CPU 크레딧으로 제한적 고성능 발휘
- 지속 CPU 작업에는 부적합
- 저렴한 비용, 제한적 성능
✅ C 계열 (c5)
- 고성능 CPU 최적화
- 컴퓨팅 집약적인 작업에 강력
- 가장 우수한 성능 대비 비용 효율
✅ M 계열 (m5)
- 균형 잡힌 범용 인스턴스
- 실험 결과에서는 비용 대비 성능이 C 계열보다 열세
결론

이번 실험은 단일 연산 집중형 API(/api/calc)를 기준으로 한 테스트로, CPU 계산 부하 중심의 작업에 특화되어 있습니다.
그 결과, 컴퓨팅 최적화 인스턴스인 C 계열 (특히 c5.large)가 뛰어난 응답 시간과 처리량, 비용 대비 성능을 보였습니다.
반면 M 계열 인스턴스 (예: m5.large, m5.xlarge)는 CPU 성능보다는 균형 잡힌 범용 처리에 강점을 가지는 유형으로, 이번 실험에서는 그 장점을 충분히 발휘하지 못했습니다.
따라서 단순히 M 계열을 '비효율적'이라고 결론짓기보다는 다음과 같은 관점이 필요합니다.
실제 서비스에서의 복합적인 I/O 작업, 예를 들어 데이터베이스 접근, 파일 처리, 네트워크 병렬 처리, 캐시 연동 등의 부하를 포함한다면 M 계열이 더 안정적일 수 있습니다.
메모리 의존도가 높은 애플리케이션에서는 C 계열보다 더 나은 퍼포먼스를 발휘할 수 있습니다.
⁉️t2가 더 옛날 버전인데 왜 t3보다 빠를까
지금 실행한 /api/calc는 매우 짧은 CPU 바운드 작업 이런 단기적 테스트에서는 t2의 크레딧을 다 쓰기 전에 테스트가 끝납니다. 따라서 평균 응답 시간이 더 낮음 장기 테스트(예: 10분 이상)나 실서비스 시나리오에선 보통 t3가 더 낫습니다. t2는 크레딧 소진 시 성능이 급락하고 t3는 지속 부하에도 일정 수준 성능 유지 합니다.(과금 조건 포함)
✅ 아쉬운점
- 가용영역을 통일하지 못해서 이로인한 차이가 발생했을 수 있습니다.
- 성능 테스트에서는 단순히 동시 접속자 수(N)와 총 요청 수(R)만 정해놓는 것보다, 다양한 변수(접속자 수, 반복 횟수, 요청 간 간격, 부하 지속 시간)를 함께 고려해 구성하는 것이 보다 현실적이고 유의미한 결과를 얻는 데 적합합니다.
✅ 추가 실험 제안
- I/O 중심 API 테스트: 파일 읽기/쓰기, 디스크 캐시 작업
- 네트워크 병렬 처리 부하 테스트: 여러 외부 API 호출 등
- 메모리 활용 테스트: 대량 JSON 파싱, pandas DataFrame 연산 등
- 실제 웹 애플리케이션 부하 시나리오 구성: DB 연동 + 비동기 요청 처리
보고서를 작성한 링크입니다 :)